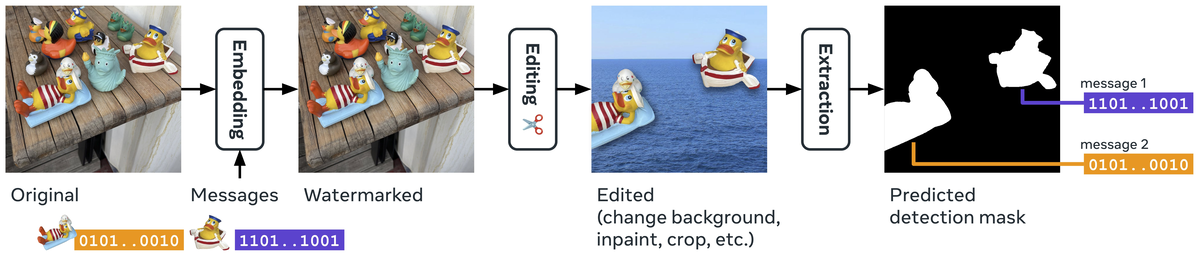
はじめに
Stack Overflowで報告されたPhi-3モデルのエラー:
AttributeError: 'DynamicCache' object has no attribute 'seen_tokens'
このエラーはtrust_remote_code=Trueにより古いリモートコードが使用されることが原因でした。
trust_remote_codeパラメータとは
trust_remote_codeは、Hugging Face transformersライブラリの重要なパラメータで、以下の役割を持ちます:
True: Hugging Face Hubからリモートコードをダウンロードして実行False: ローカルのtransformersライブラリのコードを使用
一般的に、新しいモデルや実験的なモデルではtrust_remote_code=Trueが必要な場合がありますが、既にtransformersライブラリに組み込まれたモデルでは不要です。
問題の具体例:Phi-3でのエラー
以下のコードでエラーが発生しました:
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline model = AutoModelForCausalLM.from_pretrained( "microsoft/Phi-3-mini-4k-instruct", torch_dtype="auto", trust_remote_code=True # これが問題の原因 )
エラーメッセージ:
AttributeError: 'DynamicCache' object has no attribute 'seen_tokens'
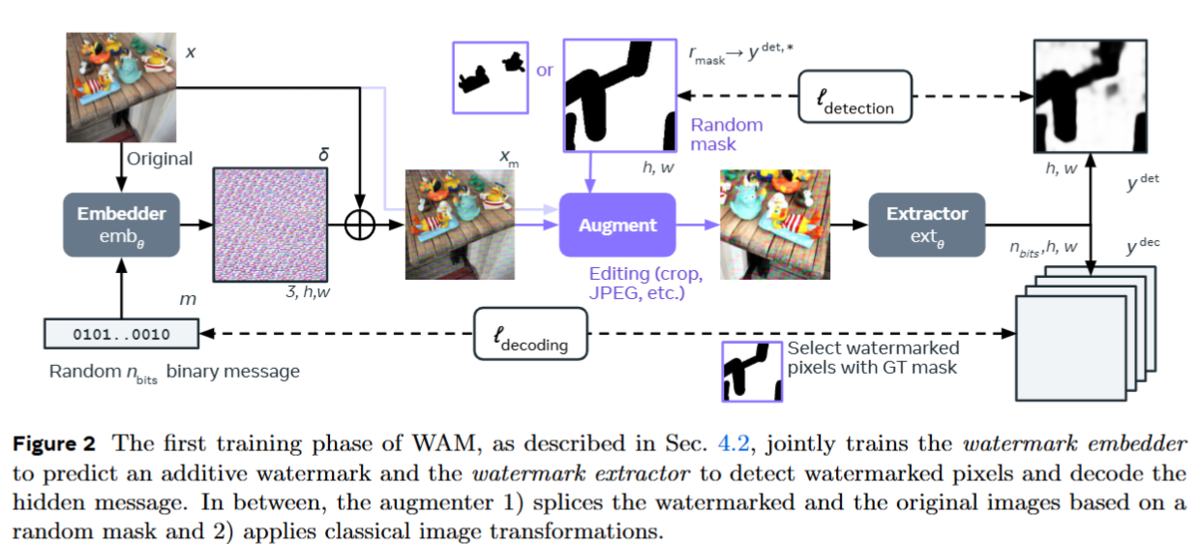
技術的解説:trust_remote_codeの処理フロー
1. エントリーポイント:AutoModelForCausalLM.from_pretrained()
ファイル: /src/transformers/models/auto/auto_factory.py:334-364
# ステップ1: コンフィグを読み込み config, kwargs = AutoConfig.from_pretrained( pretrained_model_name_or_path, return_unused_kwargs=True, code_revision=code_revision, _commit_hash=commit_hash, **hub_kwargs, **kwargs, ) # ステップ2: リモートコードとローカルコードの存在確認 has_remote_code = hasattr(config, "auto_map") and cls.__name__ in config.auto_map has_local_code = type(config) in cls._model_mapping upstream_repo = None if has_remote_code: class_ref = config.auto_map[cls.__name__] if "--" in class_ref: upstream_repo = class_ref.split("--")[0] # ステップ3: trust_remote_code値を解決 trust_remote_code = resolve_trust_remote_code( trust_remote_code, pretrained_model_name_or_path, has_local_code, has_remote_code, upstream_repo=upstream_repo, )
2. trust_remote_code値の解決ロジック
ファイル: /src/transformers/dynamic_module_utils.py:706-788
resolve_trust_remote_code関数は、ユーザーが指定したtrust_remote_codeパラメータを最終的な決定値に変換します:
def resolve_trust_remote_code( trust_remote_code, model_name, has_local_code, has_remote_code, error_message=None, upstream_repo=None ): # (一部省略) ... # ユーザーが明示的に指定していない場合(trust_remote_code=None)の自動判定 if trust_remote_code is None: if has_local_code: trust_remote_code = False # ローカルコードが存在すれば安全性を優先 elif has_remote_code and TIME_OUT_REMOTE_CODE > 0: # リモートコードのみの場合、ユーザーに対話的に確認 answer = input("Do you wish to run the custom code? [y/N] ") trust_remote_code = answer.lower() in ["yes", "y", "1"] # セキュリティチェック:リモートコードが必要なのに信頼されていない場合はエラー if has_remote_code and not has_local_code and not trust_remote_code: raise ValueError("Please pass `trust_remote_code=True` to allow custom code to be run.") return trust_remote_code
解決処理の動作例:
trust_remote_code=True: 明示的にリモートコードを使用trust_remote_code=False: 明示的にローカルライブラリのコードを使用trust_remote_code=None:has_local_code=True→trust_remote_code=Falseに設定has_remote_code=True→ ユーザーに確認を求める(対話的プロンプト)
3. コード分岐:リモートコード vs ローカルコード
ファイル: /src/transformers/models/auto/auto_factory.py:370-391
パターンA: trust_remote_code=True(リモートコードを使用)
if has_remote_code and trust_remote_code: # リモートからクラスを動的に読み込み model_class = get_class_from_dynamic_module( class_ref, pretrained_model_name_or_path, code_revision=code_revision, **hub_kwargs, **kwargs ) # ローカルコードが存在しない場合のみ、オートクラスマッピングに登録 if not has_local_code: cls.register(config.__class__, model_class, exist_ok=True) model_class.register_for_auto_class(auto_class=cls) # リモートモデルに生成機能を追加 model_class = add_generation_mixin_to_remote_model(model_class) return model_class.from_pretrained( pretrained_model_name_or_path, *model_args, config=config, **hub_kwargs, **kwargs )
パターンB: trust_remote_code=False(ローカルコードを使用)
elif type(config) in cls._model_mapping: # ローカルライブラリから対応するモデルクラスを取得 model_class = _get_model_class(config, cls._model_mapping) if model_class.config_class == config.sub_configs.get("text_config", None): config = config.get_text_config() return model_class.from_pretrained( pretrained_model_name_or_path, *model_args, config=config, **hub_kwargs, **kwargs )
4. リモートコードのダウンロードプロセス
ファイル: /src/transformers/dynamic_module_utils.py:495-617
def get_class_from_dynamic_module( class_reference: str, pretrained_model_name_or_path: Union[str, os.PathLike], # ... その他のパラメータ ) -> type: # (一部省略) ... # クラス参照から repo_id とモジュール情報を抽出 if "--" in class_reference: repo_id, class_reference = class_reference.split("--") else: repo_id = pretrained_model_name_or_path module_file, class_name = class_reference.split(".") # リモートからモジュールファイルをキャッシュ済みで取得 final_module = get_cached_module_file( repo_id, module_file + ".py", cache_dir=cache_dir, force_download=force_download, # ... その他のパラメータ ) # モジュールからクラスを取得して返す return get_class_in_module(class_name, final_module, force_reload=force_download)
5. 処理フローの全体図
AutoModelForCausalLM.from_pretrained()
│
├─ AutoConfig.from_pretrained() # コンフィグ読み込み
│
├─ リモート/ローカルコードの存在確認
│ ├─ has_remote_code = config.auto_map に該当クラスが存在
│ └─ has_local_code = ローカルマッピングに該当クラスが存在
│
├─ resolve_trust_remote_code() # trust_remote_code値を解決
│ ├─ trust_remote_code=True → 明示的にリモートコード使用
│ ├─ trust_remote_code=False → 明示的にローカルコード使用
│ └─ trust_remote_code=None → 自動判定
│ ├─ has_local_code=True → False に設定
│ └─ has_remote_code=True → ユーザーに確認
│
└─ 分岐処理
├─ has_remote_code=True かつ trust_remote_code=True
│ └─ get_class_from_dynamic_module() # リモートコードダウンロード
│ └─ get_cached_module_file() # Hubからファイル取得
│
└─ has_local_code=True
└─ _get_model_class() # ローカルライブラリから取得
根本原因:Phi-3でのAPI変更
この問題は、以下の理由で発生します:
古いリモートコード:
trust_remote_code=Trueにより、Hugging Face Hubから古いPhi-3のコードがダウンロードされるAPI変更: 古いコードでは
past_key_values.seen_tokensを使用していたが、最新のtransformersライブラリではDynamicCacheクラスからseen_tokens属性が削除されている新しいAPI: 現在は
past_key_values.get_seq_length()メソッドを使用する
ローカルライブラリ(最新)
ファイル: /src/transformers/models/phi3/modeling_phi3.py:379
# 現在のtransformersライブラリの実装 past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0 cache_position = torch.arange( past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device )
リモートコード(古い実装)
Hugging Face Hubにある古いコードでは:
# 古いリモートコードの実装(エラーの原因) if isinstance(past_key_values, Cache): cache_length = past_key_values.get_seq_length() past_length = past_key_values.seen_tokens # ← この属性がもう存在しない! max_cache_length = past_key_values.get_max_length()
解決方法
解決は簡単で、trust_remote_code=Falseに変更するだけです:
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-4k-instruct",
torch_dtype="auto",
trust_remote_code=False # Falseに変更
)
Phi-3モデルは既にtransformersライブラリに正式に組み込まれているため、リモートコードは不要で、ローカルコードを実行すればOKです。
まとめ
transformersライブラリを使用する際は、まずそのモデルが公式にサポートされているかを確認し、適切なtrust_remote_code設定を選択することが重要です。この詳細な処理フローを理解することで、同様の問題を未然に防ぎ、適切なトラブルシューティングができるようになります。


 DDR5 5600MHz (または5200MHzまたは4800MHz) ノートパソコンメモリ CT2K32G56C46S5")