Hugging Face Transformersの`trust_remote_code`パラメータで起こるAttributeError:原因と解決法
はじめに
Stack Overflowで報告されたPhi-3モデルのエラー:
AttributeError: 'DynamicCache' object has no attribute 'seen_tokens'
このエラーはtrust_remote_code=Trueにより古いリモートコードが使用されることが原因でした。
trust_remote_codeパラメータとは
trust_remote_codeは、Hugging Face transformersライブラリの重要なパラメータで、以下の役割を持ちます:
True: Hugging Face Hubからリモートコードをダウンロードして実行False: ローカルのtransformersライブラリのコードを使用
一般的に、新しいモデルや実験的なモデルではtrust_remote_code=Trueが必要な場合がありますが、既にtransformersライブラリに組み込まれたモデルでは不要です。
問題の具体例:Phi-3でのエラー
以下のコードでエラーが発生しました:
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline model = AutoModelForCausalLM.from_pretrained( "microsoft/Phi-3-mini-4k-instruct", torch_dtype="auto", trust_remote_code=True # これが問題の原因 )
エラーメッセージ:
AttributeError: 'DynamicCache' object has no attribute 'seen_tokens'
技術的解説:trust_remote_codeの処理フロー
1. エントリーポイント:AutoModelForCausalLM.from_pretrained()
ファイル: /src/transformers/models/auto/auto_factory.py:334-364
# ステップ1: コンフィグを読み込み config, kwargs = AutoConfig.from_pretrained( pretrained_model_name_or_path, return_unused_kwargs=True, code_revision=code_revision, _commit_hash=commit_hash, **hub_kwargs, **kwargs, ) # ステップ2: リモートコードとローカルコードの存在確認 has_remote_code = hasattr(config, "auto_map") and cls.__name__ in config.auto_map has_local_code = type(config) in cls._model_mapping upstream_repo = None if has_remote_code: class_ref = config.auto_map[cls.__name__] if "--" in class_ref: upstream_repo = class_ref.split("--")[0] # ステップ3: trust_remote_code値を解決 trust_remote_code = resolve_trust_remote_code( trust_remote_code, pretrained_model_name_or_path, has_local_code, has_remote_code, upstream_repo=upstream_repo, )
2. trust_remote_code値の解決ロジック
ファイル: /src/transformers/dynamic_module_utils.py:706-788
resolve_trust_remote_code関数は、ユーザーが指定したtrust_remote_codeパラメータを最終的な決定値に変換します:
def resolve_trust_remote_code( trust_remote_code, model_name, has_local_code, has_remote_code, error_message=None, upstream_repo=None ): # (一部省略) ... # ユーザーが明示的に指定していない場合(trust_remote_code=None)の自動判定 if trust_remote_code is None: if has_local_code: trust_remote_code = False # ローカルコードが存在すれば安全性を優先 elif has_remote_code and TIME_OUT_REMOTE_CODE > 0: # リモートコードのみの場合、ユーザーに対話的に確認 answer = input("Do you wish to run the custom code? [y/N] ") trust_remote_code = answer.lower() in ["yes", "y", "1"] # セキュリティチェック:リモートコードが必要なのに信頼されていない場合はエラー if has_remote_code and not has_local_code and not trust_remote_code: raise ValueError("Please pass `trust_remote_code=True` to allow custom code to be run.") return trust_remote_code
解決処理の動作例:
trust_remote_code=True: 明示的にリモートコードを使用trust_remote_code=False: 明示的にローカルライブラリのコードを使用trust_remote_code=None:has_local_code=True→trust_remote_code=Falseに設定has_remote_code=True→ ユーザーに確認を求める(対話的プロンプト)
3. コード分岐:リモートコード vs ローカルコード
ファイル: /src/transformers/models/auto/auto_factory.py:370-391
パターンA: trust_remote_code=True(リモートコードを使用)
if has_remote_code and trust_remote_code: # リモートからクラスを動的に読み込み model_class = get_class_from_dynamic_module( class_ref, pretrained_model_name_or_path, code_revision=code_revision, **hub_kwargs, **kwargs ) # ローカルコードが存在しない場合のみ、オートクラスマッピングに登録 if not has_local_code: cls.register(config.__class__, model_class, exist_ok=True) model_class.register_for_auto_class(auto_class=cls) # リモートモデルに生成機能を追加 model_class = add_generation_mixin_to_remote_model(model_class) return model_class.from_pretrained( pretrained_model_name_or_path, *model_args, config=config, **hub_kwargs, **kwargs )
パターンB: trust_remote_code=False(ローカルコードを使用)
elif type(config) in cls._model_mapping: # ローカルライブラリから対応するモデルクラスを取得 model_class = _get_model_class(config, cls._model_mapping) if model_class.config_class == config.sub_configs.get("text_config", None): config = config.get_text_config() return model_class.from_pretrained( pretrained_model_name_or_path, *model_args, config=config, **hub_kwargs, **kwargs )
4. リモートコードのダウンロードプロセス
ファイル: /src/transformers/dynamic_module_utils.py:495-617
def get_class_from_dynamic_module( class_reference: str, pretrained_model_name_or_path: Union[str, os.PathLike], # ... その他のパラメータ ) -> type: # (一部省略) ... # クラス参照から repo_id とモジュール情報を抽出 if "--" in class_reference: repo_id, class_reference = class_reference.split("--") else: repo_id = pretrained_model_name_or_path module_file, class_name = class_reference.split(".") # リモートからモジュールファイルをキャッシュ済みで取得 final_module = get_cached_module_file( repo_id, module_file + ".py", cache_dir=cache_dir, force_download=force_download, # ... その他のパラメータ ) # モジュールからクラスを取得して返す return get_class_in_module(class_name, final_module, force_reload=force_download)
5. 処理フローの全体図
AutoModelForCausalLM.from_pretrained()
│
├─ AutoConfig.from_pretrained() # コンフィグ読み込み
│
├─ リモート/ローカルコードの存在確認
│ ├─ has_remote_code = config.auto_map に該当クラスが存在
│ └─ has_local_code = ローカルマッピングに該当クラスが存在
│
├─ resolve_trust_remote_code() # trust_remote_code値を解決
│ ├─ trust_remote_code=True → 明示的にリモートコード使用
│ ├─ trust_remote_code=False → 明示的にローカルコード使用
│ └─ trust_remote_code=None → 自動判定
│ ├─ has_local_code=True → False に設定
│ └─ has_remote_code=True → ユーザーに確認
│
└─ 分岐処理
├─ has_remote_code=True かつ trust_remote_code=True
│ └─ get_class_from_dynamic_module() # リモートコードダウンロード
│ └─ get_cached_module_file() # Hubからファイル取得
│
└─ has_local_code=True
└─ _get_model_class() # ローカルライブラリから取得
根本原因:Phi-3でのAPI変更
この問題は、以下の理由で発生します:
古いリモートコード:
trust_remote_code=Trueにより、Hugging Face Hubから古いPhi-3のコードがダウンロードされるAPI変更: 古いコードでは
past_key_values.seen_tokensを使用していたが、最新のtransformersライブラリではDynamicCacheクラスからseen_tokens属性が削除されている新しいAPI: 現在は
past_key_values.get_seq_length()メソッドを使用する
ローカルライブラリ(最新)
ファイル: /src/transformers/models/phi3/modeling_phi3.py:379
# 現在のtransformersライブラリの実装 past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0 cache_position = torch.arange( past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device )
リモートコード(古い実装)
Hugging Face Hubにある古いコードでは:
# 古いリモートコードの実装(エラーの原因) if isinstance(past_key_values, Cache): cache_length = past_key_values.get_seq_length() past_length = past_key_values.seen_tokens # ← この属性がもう存在しない! max_cache_length = past_key_values.get_max_length()
解決方法
解決は簡単で、trust_remote_code=Falseに変更するだけです:
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-4k-instruct",
torch_dtype="auto",
trust_remote_code=False # Falseに変更
)
Phi-3モデルは既にtransformersライブラリに正式に組み込まれているため、リモートコードは不要で、ローカルコードを実行すればOKです。
まとめ
transformersライブラリを使用する際は、まずそのモデルが公式にサポートされているかを確認し、適切なtrust_remote_code設定を選択することが重要です。この詳細な処理フローを理解することで、同様の問題を未然に防ぎ、適切なトラブルシューティングができるようになります。
論文まとめ:Temporal Chain of Thought: Long-Video Understanding by Thinking in Frames
aistudioでGeminiと対話しながら、表題の論文をまとめました。(個人的に、NotebookLMよりもaistudioの方がUIが好みです)
この論文はどんなもの?

- 長時間動画を対象としたVLMの推論能力向上を目指し、新たな推論戦略「Temporal Chain of Thought (TCoT)」を提案
- 動画の質問応答タスクを「関連フレームの抽出」と「抽出フレームに基づく回答生成」の2段階に分解し、VLM自身にプロンプティングを通じて思考の連鎖を実行させることで、無関係なコンテキストによる性能劣化を抑制
- 注目すべきは、このアプローチにより、より短いコンテキスト長のVLMが、700Kトークンもの広大なコンテキストを持つモデルを凌駕する性能を達成した点であり、これはモデルの物理的なコンテキスト長以上に、推論戦略そのものが性能を左右することを示唆している
既存研究の課題
この論文が解決しようとする課題は、主に以下の二点に集約される。
- 長コンテキストVLMの課題
- 最新のVLMは数百から数千フレームもの入力を処理できますが、多くの研究(例えばLost in the middle)で示されているように、コンテキストが長くなるにつれて、モデルが無関係または誤解を招く内容に圧倒され、結果として精度が飽和、あるいは低下する
- 複数のモデルを組み合わせる手法の課題
- 複数の専用モデルを組み合わせる従来の手法(例えばVideoAgent)は、ビデオをキャプションなどのテキスト中間表現に変換する際に情報が失われる上、多段なパイプライン構成によりシステムが複雑化し、各段階でのエラーが伝播・蓄積しやすい
提案手法の肝は?

- CoTの時間軸への応用
- Chain of Thoughtは、入力 → 出力という直接的な思考をするのではなく、入力 → 思考プロセス → 出力のように、多段階のステップへ分解する。提案手法であるTemporal CoTでは、動画QAタスクにおける「思考プロセス」を、長大な動画から質問へ回答するための根拠となるフレームを時系列に抽出することとして設計。
- 具体的には、質問qと動画xに基づいて最も関連性の高い情報を抽出し、凝縮されたコンテキストcを作成するコンテキスト集約ステージと、凝縮コンテキストcを使って、質問qに対する最終的な回答aを生成する回答生成ステージから構成されるアーキテクチャを設計
- 分割統治にもとづくDynamic Segment TCoT
- VLMのコンテキスト長に収まらない動画に対して、時間的に重複しないセグメントに分割して並列かつ独立にコンテキストを抽出、全てのセグメントのコンテキストを統合する
- これにより、TCoTを長時間の動画にも適用することが可能となる
提案手法の有効性はどのように評価した?
- 主要ベンチマークデータセットでのSOTA評価
- LVBench, Egoschema, NEXT-QA, OpenEQAを使用
- Ablation Study
- TCoTを構成する各要素(コンテキスト集約、フレーム選択方法など)が、本当に性能向上に寄与しているのか。
- 一般化能力の評価
- TCoTが、Gemini 1.5 Flash以外のVLMでも有効に機能するか。
有効性評価により得られた結論は?
- 圧倒的な性能と汎用性
- TCoTは、平均68分の超長尺ビデオを含む4つの多様なベンチマーク全てで既存の最先端(SOTA)性能を大幅に更新。この結果は、TCoTが特定のタスクやデータに依存しない、極めて汎用性の高いアプローチであることを証明している
- 設計の正当性と効率性:
- 「VLM自身に賢くフレームを選ばせる」というTCoTの核心的な設計は、単純なサンプリングや他の代替手法よりも明らかに優れており、性能向上の直接的な要因である。また、同じ計算コストを投じた場合でも標準的な推論を上回り、計算リソースをより効率的に活用できることが示された
- モデルへの一般化能力:
ReActの思考過程をGoogle Colabで実行して確認する
前回、ReActの論文をまとめましたが、実際にどのような思考と行動を行うのかを、公式のコードをColabで実行できるように修正して、確認してみます。
実装の詳細解説
ReActのコア実装
OpenAIのモデルは、GPT-4oを使ってみます。
def llm(prompt, stop=["\n"]): messages = [{"role": "user", "content": prompt}] response = openai.ChatCompletion.create( model="gpt-4o", messages=messages, temperature=0, max_tokens=100, top_p=1, frequency_penalty=0.0, presence_penalty=0.0, stop=stop ) return response['choices'][0]['message']['content']
def webthink(idx=None, prompt=webthink_prompt, to_print=True): question = env.reset(idx=idx) prompt += question + "\n" n_calls, n_badcalls = 0, 0 for i in range(1, 8): n_calls += 1 # Thoughtの生成 thought_action = llm(prompt + f"Thought {i}:", stop=[f"\nObservation {i}:"]) try: thought, action = thought_action.strip().split(f"\nAction {i}: ") except: # パース失敗時の処理 n_badcalls += 1 n_calls += 1 thought = thought_action.strip().split('\n')[0] action = llm(prompt + f"Thought {i}: {thought}\nAction {i}:", stop=[f"\n"]).strip() # アクションの実行 obs, r, done, info = step(env, action[0].lower() + action[1:]) obs = obs.replace('\\n', '') # プロンプトの更新 step_str = f"Thought {i}: {thought}\nAction {i}: {action}\nObservation {i}: {obs}\n" prompt += step_str if to_print: print(step_str) if done: break return r, info
webthinkがReActの思考、行動の繰り返し処理になっています。ここでは、最大7回の思考、行動のループを行います。llmに与えられるプロンプトは、instructionと6つのfew shotの例(jsonファイル内のwebthink_simple6)、それに加えて質問文、最後にThought {i}になっています。instructionは、指示文の他に、3つのActionとしてSearchとLookup、Finishが説明されています。また、2回目以降では、これらの内容とThoughtの結果、Action、Observationが追加されて次のThoughtが含まれます。このようにして、各ループで前の思考と行動、観察結果が累積的にプロンプトに追加されて、文脈を維持しながら次の思考を行なっていきます。
アクションの種類
ReActでは3種類のアクションが利用可能です:
1. Search[entity]
Action 1: Search[Barack Obama]
- Wikipedia上で特定のエンティティを検索
- 存在する場合は最初の段落を返す
- 存在しない場合は類似エンティティを提案
2. Lookup[keyword]
Action 2: Lookup[birth date]
- 現在の文章からキーワードを含む次の文を検索
- 詳細情報を段階的に取得する際に有効
3. Finish[answer]
Action 3: Finish[October 4, 1961]
- 最終的な答えを返してタスクを完了
- 推論プロセスの終了を示す
推論プロセスの例
質問は、「作家のデイビッド・チャノフは、どの大統領の下で英国大使を務めたアメリカ海軍提督と協力しましたか?」 最初の思考でデイビッドチャノフを検索して、協力関係にあった提督を見つける。それから、その提督がいつ、どの大統領のもとで英国大使をしたかを調べる、となっています。 なので Search[David Chanoff]。結果の中からWilliam J. CroweというCollaboratorを見つけ、次の思考、行動でWilliam J. Croweを調べ、最後のループでBill Cllintonのもとで英国大使をしたとわかったため、Finishになっています。結果としてこの例では正解を導けています。
3824 Question: Author David Chanoff has collaborated with a U.S. Navy admiral who served as the ambassador to the United Kingdom under which President?
Thought 1: I need to search for David Chanoff and find the U.S. Navy admiral he collaborated with. Then, I need to find out when this admiral served as the ambassador to the United Kingdom and under which President.
Action 1: Search[David Chanoff]
Observation 1: David Chanoff (born November 15, 1943, in Philadelphia) is an American author of non-fiction work. His work has typically involved collaborations with the principal protagonist of the work concerned. His collaborators have included Augustus A. White, Joycelyn Elders, Đoàn Văn Toại, William J. Crowe, Ariel Sharon, Kenneth Good and Felix Zandman, among others.
Thought 2: David Chanoff collaborated with William J. Crowe, who is a U.S. Navy admiral. I need to search for William J. Crowe to find out when he served as the ambassador to the United Kingdom and under which President.
Action 2: Search[William J. Crowe]
Observation 2: William James Crowe Jr. (January 2, 1925 – October 18, 2007) was a United States Navy admiral and diplomat who served as the 11th chairman of the Joint Chiefs of Staff under presidents Ronald Reagan and George H. W. Bush, and as the ambassador to the United Kingdom and Chair of the Intelligence Oversight Board under President Bill Clinton.. Crowe was born in La Grange, Kentucky, on January 2, 1925.
Thought 3: William J. Crowe served as the ambassador to the United Kingdom under President Bill Clinton. Therefore, the U.S. Navy admiral that David Chanoff collaborated with served as the ambassador to the United Kingdom under President Bill Clinton.
Action 3: Finish[Bill Clinton]
Observation 3: Episode finished, reward = 1
{'steps': 3, 'answer': 'Bill Clinton', 'gt_answer': 'Bill Clinton', 'question_idx': 3824, 'reward': True, 'em': True, 'f1': 1.0}
実行結果を確認してみて
Seachアクションは、Wikiの最初の段落を返すようになっていて、必要な情報がそこに含まれないと、次のような問題が発生する可能性があります。
- 情報が不十分で正しい推論ができない
- Lookup[keyword]で詳細を探す必要があるが、適切なキーワードを選択できない
- 関連する別のエンティティを検索する必要があるが、適切な推論ができない
実際、インデックスを変えて別の質問を試してみると、回答を得ることができない場合も比較的ありました。複雑な質問応答タスクでReActが機能するためには、どのようなツールを用意するかも非常に重要になりそうです。
論文まとめ:ReAct: Synergizing Reasoning and Acting in Language Models
Gemini2.5 Proをお供にして、論文をまとめていきます。
この論文はどんなもの?
言語モデルに『思考』(Reasoning)と『行動』(Acting)を交互に繰り返させることで、外部情報に基づいて賢く計画を立てながら、人間のようにタスクを解決させる新しい手法(ReAct)を提案したものです。
既存研究の課題
既存研究には2つの流れがありました。
- 思考の連鎖 (CoT): LLMに思考プロセスを文章化させる「考える」研究。
- 行動生成モデル: LLMに行動コマンドを生成させる「行動する」研究。
それぞれの課題は
- CoTの課題: 外部情報にアクセスできず、事実と異なる情報(ハルシネーション)を生成してしまうこと。
- 行動生成モデルの課題: 高度な計画立案が苦手で、複雑なタスクや予期せぬ事態に対応できないこと。
提案手法の概要と特徴
ReActは、LLMに「思考(Thought)」、「行動(Act)」、「観察(Observation)」のサイクルを繰り返させます。
- 思考(Thought): タスクの分解、計画の立案、進捗の確認、例外処理など、次に行うべき行動を決定するための内的な言語推論を生成させます。
- 行動(Act): 思考に基づいて、Wikipedia APIの検索や、ゲーム環境内のコマンド実行など、外部環境に働きかける具体的な行動を生成させます。
- 観察(Observation): 行動の結果として外部環境から得られた情報(検索結果やゲームの状態変化など)をLLMにフィードバックします。
この「思考→行動→観察」のループを繰り返すことで、LLMは動的に計画を修正し、外部情報に基づいて推論を更新しながら、タスクを遂行します。
提案手法の具体的なアイデア
ReActの核心は、LLM(大規模言語モデル)の「行動の選択肢(アクションスペース)」を拡張するという、シンプルかつ強力なアイデアにあります。
- 「思考」を新しいアクションとして追加
- 従来のAIの行動は、search[...] や go to... のように、外部環境を直接変化させるものだけでした。ReActはここに、「頭の中で考える(言葉にする)」という新しい行動(思考アクション)を追加します。この「思考」は外部環境を変えませんが、AI自身の次の行動方針を決定するための内部状態(文脈)を更新します。
- 複雑な問題の分解
- この仕組みにより、「生の観測データから直接、最適な行動を予測する」という非常に困難な問題を、LLMが得意な2つのより簡単な問題に分解します。
- ステップ1: 生の観測データから、次に何をすべきかという「思考テキスト」を生成する。
- ステップ2: 生成した「思考テキスト」を手がかりに、具体的な行動を生成する。
- この仕組みにより、「生の観測データから直接、最適な行動を予測する」という非常に困難な問題を、LLMが得意な2つのより簡単な問題に分解します。
- Few-shot Promptingによる実現
- この一連の「思考→行動→観察」という複雑な振る舞いを、モデルを再学習させることなく、わずか数例の模範的な対話(プロンプト)をLLMに見せるだけで実現します。LLMは、そのパターンを模倣して、新しいタスクにも同様の思考と行動のサイクルを適用できるようになります。
ReActの具体的な「思考・行動・観察」サイクル
HotpotQAタスク
質問: 「Apple Remote以外に、それが元々操作対象だったプログラムを制御できるデバイスは何ですか?」
この複雑な質問に対し、ReActは以下のようにサイクルを実行します。
サイクル 1: タスクの分解と最初の情報収集
思考 (Thought 1):
"I need to search Apple Remote and find the program it was originally designed to interact with." (まず「Apple Remote」を検索して、それが元々どのプログラムを操作するために設計されたかを見つけよう。)
行動 (Act 1):
Search[Apple Remote]観察 (Obs 1):
"The Apple Remote is a remote control... originally designed to control the Front Row media center program." (Apple Remoteはリモコンで...元々はFront Rowというメディアセンタープログラムを操作するために設計されました。)
- 役割: 行動の結果得られた事実。これでサブタスク①が解決しました。
サイクル 2: 次の目標設定と情報収集
思考 (Thought 2):
"Apple Remote was originally designed to control the Front Row media center program. I need to search Front Row next and find what other device can control it." (Apple Remoteの操作対象はFront Rowだった。次はFront Rowを検索して、それを操作できる他のデバイスを見つけよう。)
- 役割: サイクル1の観察結果を解釈し、サブタスク②を実行するための具体的な行動計画を立てます。
行動 (Act 2):
Search[Front Row]- 役割: 新しい計画に基づき、次の情報収集を行います。
観察 (Obs 2):
"Could not find [Front Row]. Similar: ['Front Row (software)', ...]" ([Front Row]は見つかりませんでした。類似項目: ['Front Row (software)', ...])
- 役割: 検索が失敗したという予期せぬ結果。
サイクル 3: エラーからの回復と計画修正
思考 (Thought 3):
"Front Row is not found. I need to search Front Row (software)." (Front Rowが見つからなかった。類似項目にあった「Front Row (software)」で検索し直す必要があるな。)
- 役割: 予期せぬ観察結果(エラー)を認識し、それを乗り越えるための計画修正を行います。これがReActの強力な点です。
行動 (Act 3):
Search[Front Row (software)]- 役割: 修正した計画に基づいて行動を再実行します。
観察 (Obs 3):
"Front Row (software) is controlled by an Apple Remote or the keyboard function keys." (Front Row (software)は、Apple Remoteまたはキーボードのファンクションキーで操作されます。)
- 役割: 最終的な答えを含む決定的な情報を入手しました。
サイクル 4: 最終的な答えの統合と出力
思考 (Thought 4):
"Front Row (software) is controlled by an Apple Remote or the keyboard function keys. So the answer is keyboard function keys." (Front Row (software)はApple Remoteかキーボードで操作できる。質問は「Apple Remote以外」だから、答えはキーボードのファンクションキーだ。)
- 役割: これまでの全ての情報を統合し、質問の意図("Apple Remote以外")を考慮して、最終的な結論を導き出します。
行動 (Act 4):
Finish[keyboard function keys]- 役割: 結論を行動として出力し、タスクを完了します。
提案手法の有効性はどのように評価した?
多様な性質を持つ4つのベンチマークと、比較実験によって詳細に検証されています。
- ベンチマーク
- HotpotQA: 複数の文書をまたぐ推論が必要な質問応答。
- FEVER: 提示された主張が事実かどうかを検証するタスク。
- ALFWorld: テキストベースで指示された家事タスク(例:「ナイフを洗ってカウンターに置く」)をシミュレーション環境内で実行するゲーム。
- WebShop: ECサイトを模した環境で、ユーザーの指示に合う商品を検索・購入するタスク。
- 比較対象
- Standard: 質問に直接回答するベースライン。
- CoT (Reasoning-Only): 思考の連鎖のみで回答を導出。
- Act-Only: 思考を挟まず、行動のみを連続して生成。
- 専門エージェント: ALFWorldでは模倣学習ベースのBUTLER、WebShopでは模倣学習+強化学習ベースのエージェントと比較。これらは大量の専門データで学習されています。
- 具体的な実験結果:
- ALFWorldにおいて、ReActはタスク成功率71%を達成し、Act-Only (45%) や、10万以上のデータで学習した専門エージェントBUTLER (37%) を圧倒しました。
- WebShopにおいても、ReActは成功率40%を達成し、Act-Only (30.1%) や専門エージェント (28.7%) を上回りました。
- HotpotQAでは、CoTがしばしば事実と異なる情報(ハルシネーション)に基づいて誤答するのに対し(失敗の56%がハルシネーション)、ReActは外部情報で推論を補強するため、ハルシネーションによる失敗はほぼ0%でした。
有効性の評価により得られた結論は?
推論は行動の質を高める: ReActはAct-Onlyを一貫して上回っており、思考はより効果的な行動選択に不可欠であることが証明されました。
ReActはCoTのハルシネーション問題を克服する: 質的分析(Table 2)から、CoTの失敗の主要因(56%)はハルシネーションであることが明らかになりました。一方、ReActは外部の事実に基づいて推論するため、ハルシネーションをほぼゼロに抑え、より信頼性が高いことが示されました。
内部知識と外部知識の相補性: CoTは柔軟な推論が得意で、ReActは事実に即した行動が得意という、両者にはトレードオフの関係があります。そして、この2つを組み合わせたハイブリッド戦略が、単独の手法よりも常に高い性能を発揮することから、内部知識と外部知識を相乗的に活用することが最適であると結論付けられました。
ReActはデータ効率の良い学習スキルである: ファインチューニングの実験(Figure 3)では、単に答えを記憶させるStandardやCoTのファインチューニングよりも、「Wikipediaを使って情報を探す」というスキルを学習させるReActやActのファインチューニングの方が、はるかに高い性能を示しました。これは、ReActが単なる知識の暗記ではなく、汎用的な問題解決スキルをモデルに与えることを示唆しています。
ReActは専門エージェントを凌駕する: ALFWorldとWebShopの両方で、ReActはわずか数例のプロンプトだけで、膨大なデータで学習した専門エージェントの性能を大幅に上回りました。これは、ReActが非常にデータ効率が良く、高い汎化性能を持つことを証明しています。LLMの事前知識を「思考」で引き出すことが、大量のタスク特化データよりも強力である可能性を示唆しています。
「思考」はタスク成功に不可欠である: 全てのタスクで、ReActはAct-Onlyを圧倒しています。質的な分析から、Act-Onlyはタスクの目標を途中で見失ったり、サブゴールを正しく分解できなかったりすることが失敗の主な原因であることが分かりました。これは、長期的な行動計画が求められるタスクにおいて、思考による進捗管理と計画立案が決定的に重要であることを示しています。
高レベルで柔軟な「思考」こそが価値の源泉である: 単純な思考しかできないReAct-IMは、ReActよりも大幅に性能が劣りました。ReAct-IMは、常識を活用して探索場所を推測したり、サブゴール間の遷移を論理的に判断したりすることができないため、失敗することが多かったのです。この結果は、ReActの強みが単に思考を挟むことにあるのではなく、その思考が柔軟で高レベルな推論(常識の活用、戦略立案など)を含んでいることにあると結論付けています。
最後に
最近、エージェント研究に関する論文をいくつか見ていて、そこで参照されていたこともあり、精読をしてみました。 引用数も多く、LLMエージェント研究における重要な論文だと思いますので、この分野に興味のある方は読んでいただくと良いのではないかと思います。
【体験記】MSI公認サポート店でゲーミングPCのメモリを増設
JAXをソースからビルドしようとしたら、メモリ不足のエラーになったため、メモリ増設を考えていました。自分で増設することも出来なくはないですが、製品保証が切れてしまう(裏側パネルのネジを取るために封印シールを剥がすことになるため)ので、MSI公認サポート店でメモリ増設をしてもらうことにしました。
MSI公認サポート店は、MSIが公式に認めた増設サポートを行ってくれる店舗で、製品保証を維持したままメモリ増設をしてもらえます。
Webで検索してみると、自分でメモリ増設をしている動画などは見つかるのですが、意外に公認サポート店で増設した記事は見つからなかったので、一例として公開しようと思います。
今回増設をしたのはCyborg-15-A13VFK-4125JP、最大64GBまでの増設が可能なモデルです。
また、増設をしてもらう公認サポート店は、ヨドバシカメラを選択しました。
増設用メモリの購入
ヨドバシカメラの場合、増設作業と同時に購入することも出来るみたいですが、私はAmazonで事前に購入して持っていきました。私が購入した時は27000円ほどでした。
 DDR5 5600MHz (または5200MHzまたは4800MHz) ノートパソコンメモリ CT2K32G56C46S5")
増設
サポート受付デスクでPC本体と電源を渡して増設作業をお願いします。増設後、動作確認をしてもらうためのパスワードを教える必要があるので、事前にテンポラリのアカウントとパスワードを設定しておきました。
店舗や時間帯によって異なるとは思いますが、作業時間は約3時間ほどでした。
料金
製品保証を維持したままの増設の場合、税込で5500円でした。ヨドバシカメラのポイントでも支払うことができます。
まとめ
MSI公認サポート店のヨドバシカメラでメモリ増設した経験について、一例として紹介しました。参考にしていただければと思います。
MetaのWatermark Anything Modelの論文を読み解く
Metaが画像電子透かし技術に関する論文を発表しました。MetaのAnything Modelといえば、Segment Anything Modelがありますが、今回の論文はWatermark Anything Model。一体どのような技術なのか?論文の内容をまとめてみました。
Introのまとめ
画像電子透かし技術は、人間の目には見えない形で画像に情報を埋め込む技術です。従来は著作権保護などを目的としていましたが、近年のAI生成画像の普及に伴い、その用途は大きく変化しています。
ホワイトハウスの行政命令やEUのAI法など、各国政府はAI生成コンテンツの識別を容易にするための規制を導入しており、電子透かしはそのための重要な手段として注目されています。
しかし、従来の電子透かし技術は、画像の一部を切り貼りする「スプライシング」などの操作に対して脆弱です。例えば、電子透かしが埋め込まれた画像の一部だけを切り出して別の画像に貼り付けた場合、従来技術では電子透かしの検出が困難になります。
この論文では、これらの課題を解決するために、電子透かしをセグメンテーションタスクとして再定義した「Watermark Anything Model(WAM)」を提案しています。WAMは、画像全体ではなくピクセルごとに電子透かしの有無を判断し、埋め込まれたメッセージを抽出します。これにより、スプライシングされた画像でも電子透かしの検出・復号が可能になります。
WAMは2段階の学習プロセスを経てトレーニングされます。最初のフェーズでは低解像度画像を用いてembedderとextractorを事前学習します。embedderは、任意のn-bitメッセージを透かし信号に変換し、画像に埋め込みます。augmentorは、画像の一部に電子透かしをランダムにマスクし、その結果を一般的な処理技術(トリミング、サイズ変更、圧縮など)で補強する。一方、extractorは画像からピクセルごとに透かしの有無を判定し、メッセージを復元します。検出損失と復号損失が、学習目標として使用されます。
フェーズ2の焦点は、視認性の最小化と多重透かしへの対応です。より人間の視覚システムに合わせた、自然で目立たない透かしの埋め込みを実現します。同時に、1枚の画像に複数のメ ッセージを埋め込む能力も獲得します。この2段階の学習は、従来のadversarial networksやdivergent objectiveと比較して、不安定になりにくい。また、電子透かし画像と非電子透かし 画像の両方で抽出器を学習させる。これにより、検出の性能とロバスト性が向上する。
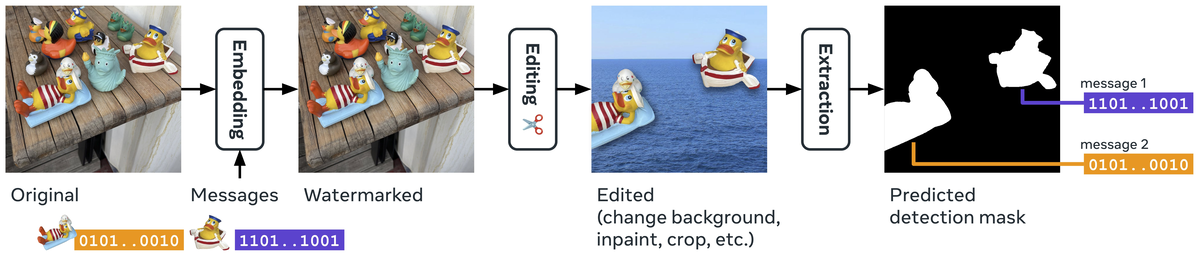
実験では、透かし検出と複合の通常のタスクについて、低解像度画像と高解像度画像で既存手法と比較し、WAMが知覚不可能性とロバスト性で競争力のある性能を達成することを示している。また、通常とは異なるタスクとして、Localization精度と単一の画像からの複数の透かしを検出・複合する能力も評価しています。
Watermark Anything Models
Model構成
WAMは、透かし埋め込み器と透かし抽出器 という2つのモデルから構成されます。
透かし埋め込み器(embedder :  )
)
embedderは、画像にメッセージを埋め込む役割を担います。その構造は、エンコーダ、メッセージ・ルックアップテーブル、デコーダの3つの要素からなります。
- エンコーダ
:入力画像を潜在空間に圧縮します。ここではLDM (Latent Diffusion Models) の変分オートエンコーダのアーキテクチャがベースとして使用されています。
- メッセージ・ルックアップテーブル
:埋め込みたいメッセージをテンソル表現に変換します。メッセージの各ビットは、その位置と値に応じてルックアップテーブルから変換される。
の埋め込みベクトルは平均化された後、潜在表現の空間サイズに合わせたテンソルになるようにリピートされます
。画像の潜在表現と連結されて、
の形状のテンソルとなる。
- デコーダ
: エンコーダからの画像潜在表現とルックアップテーブルからのメッセージテンソルを連結したものを受け取り、透かし信号
を生成します。この信号は、元の画像にスケーリングされて加算されます。スケーリング係数
は 透かし強度 と呼ばれ、元の画像への変更の度合いを制御します。最終的な透かし入り画像は、
として計算されます。
透かし抽出器(extractor:  )
)
extractorは、透かし入り画像から透かしの有無を検出し、埋め込まれたメッセージを復号する役割を担います。アーキテクチャはSETRやSegment Anythingと同様に、ViTエンコーダとピクセルデコーダの組み合わせで構成され、各ピクセルに対して次元のベクトルを出力します。
高解像度
WAMは固定解像度で動作しますが、高解像度画像にも対応可能です。埋め込み時には、入力画像を
にリサイズし、透かし信号を生成、その後でバイリニア補完により元の解像度に戻します。抽出時も同様にリサイズを行います。この方法により、低解像度画像で学習したモデルを高解像度画像に適用することが可能になり、学習に必要な計算コストを大幅に削減できます。
WAMの学習: first training phase
WAMの最初の学習フェーズでは、透かし埋め込み器と透かし抽出器を共同で学習します。その中で、 1)電子透かし画像と元画像をランダムなマスクに基づいてスプライスし、2)古典的な画像変換を適用します。以下は、詳細なフローを図で示したものです。
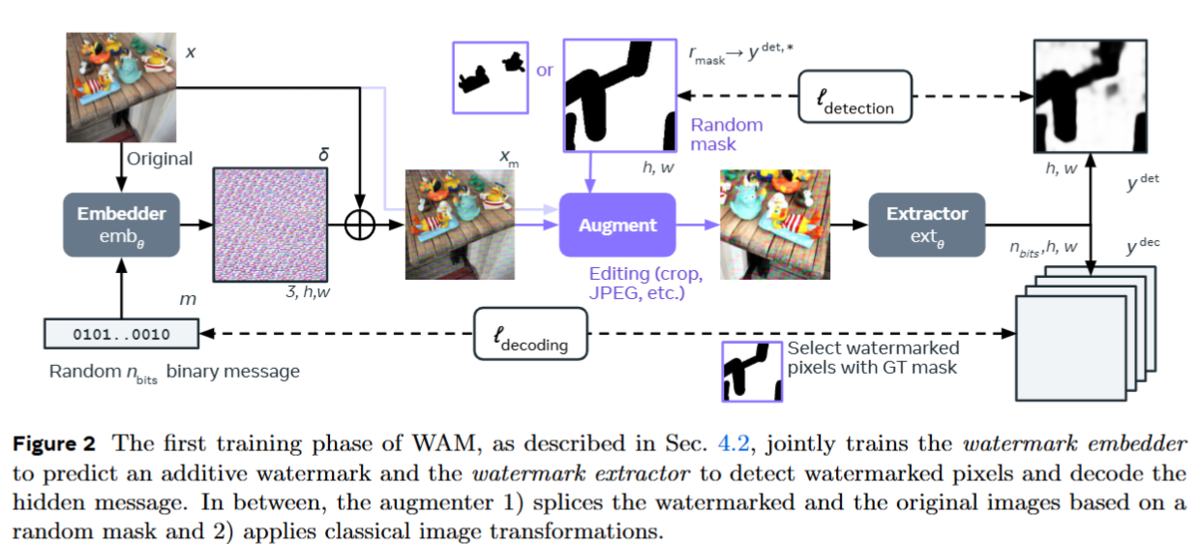
スプライシングで使われるマスクは、全領域、矩形、不規則な形状、そして学習データセットから得られるオブジェクトのセグメンテーションマップからランダムに選択されます。マスクをとすると、スプライス後の画像は
として計算されます。
は要素毎の積。
画像変換では、幾何学的な変換と値調整(ガウシアン、メディアンフィルターなど)が適用されます。幾何学変換は、透かし位置を追跡するため、マスクにも適用されます。
WAMの学習は、検出損失()と復号損失(
)の線形結合で定義される目的関数
を最小化することで行われます。
WAMの学習:Second training phase
WAMの学習の次のフェーズでは、最初のフェーズで学習したモデルをさらに洗練させ、視認性の低減と複数透かしの埋め込みという2つの重要な課題に対処します。
視認性の低減
第二フェーズではJND (Just-Noticeable-Difference) マップを活用します。JNDマップは、各ピクセルにおいて人間が知覚できる最小の人工物のモデルで、例えば平坦な領域の人工物はテクスチャのある領域よりも知覚しやすい。透かしを埋め込む際に、このJNDマップを使用することで、透かしの強度を変調して埋め込むことが可能になります。
複数透かしの埋め込み
最初のフェーズの学習では単一のメッセージしか使用されないため、異なるメッセージが埋め込まれた領域でも同じメッセージを復号する傾向があります。これを改善するために、第二フェーズでは複数のマスクを用いて学習を行います。それぞれのマスク領域に異なるメッセージを埋め込むことで、複数透かしの埋め込みに対応します。マスクの数は1から3個までで、それぞれの確率は0.6, 0.2, 0.2となっています(詳細は付録D.2)。検出損失 は、全てのマスクの和集合を正解データとして計算されます。復号損失
は、各メッセージに対して個別に計算され、その合計が全体の損失となります。
実験と結果のまとめ
この論文では、提案手法であるWAMの評価にあたり、4つの主要な項目を評価しています。
Quality
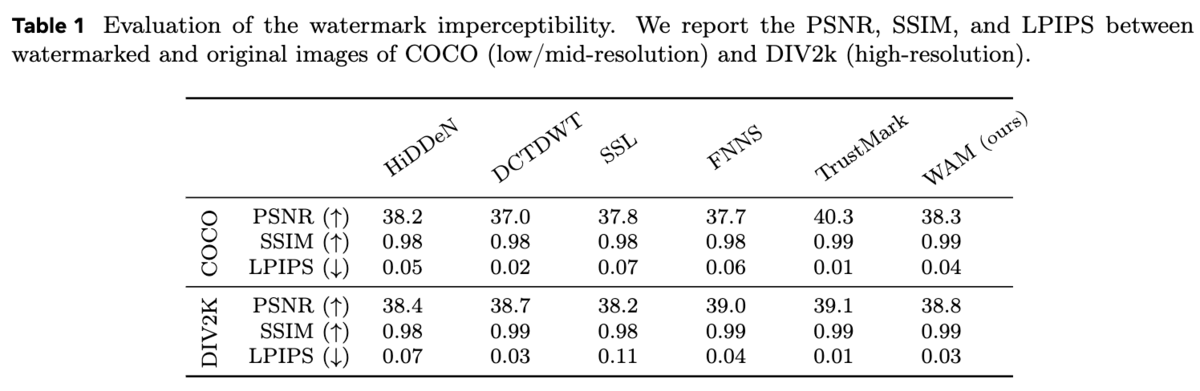
WAMによって透かしが入った画像が、元の画像と比べてどれくらい画質が変化するのか、つまり画質への影響を評価するために、PSNR、SSIM、LPIPSという3つの指標を用いて定量的に比較しています。
表1の結果から、WAMは高い画質を維持していることがわかります。これは、人間の視覚特性を考慮したJNDマップを用いることで、視覚的に敏感な領域には透かしの影響を抑え、そうでない領域に巧妙に透かしを埋め込むことで実現されています。Appendix Fには、COCOデータセットとDIV2kデータセットを用いた透かし入り画像の例が示されており、視覚的な品質の高さを確認できます。
Detection and Decoding
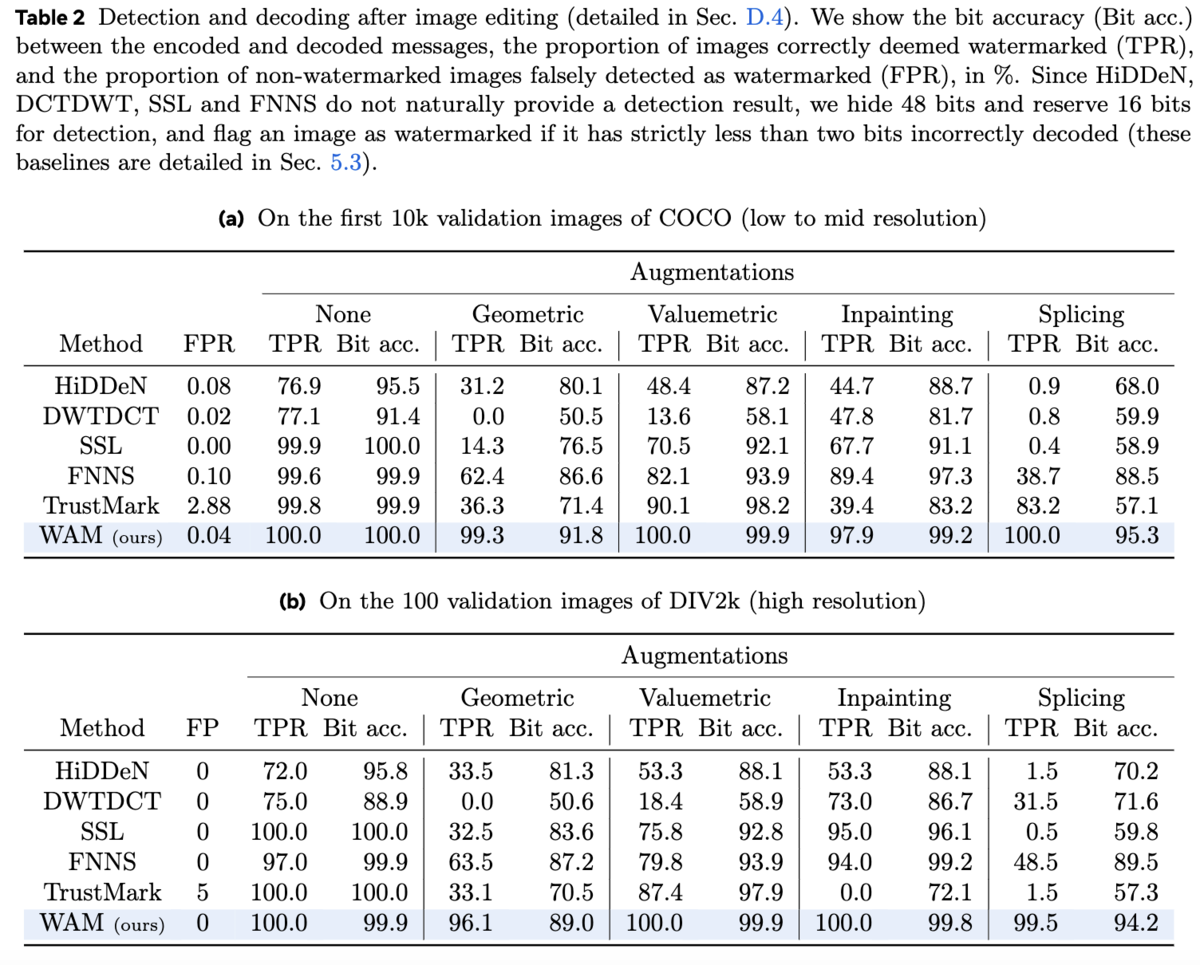
WAMの検出能力と復号能力を評価するため、DCTDWT、HiDDeN、TrustMark、SSL、FNNSといった既存の電子透かし手法と比較実験を行っています。 表2aと2bは、それぞれ低解像度/中解像度画像(COCO検証セットの最初の1万枚)と高解像度画像(DIV2k検証セット)における検出結果と復号結果を示しています。 どちらのデータセットにおいても、WAMは既存手法と比較して競争力のある性能を示し、特に従来の幾何学的変換や画質調整に対しては、より高いロバスト性を示しました。さらに重要なのは、他の手法が90%以上の真陽性率とビット精度を達成できなかったスプライシングやインペインティングに対して、WAMは優れた性能を発揮したことです。これは、WAMが高解像度画像やインペインティングに対する明示的な学習を行なっていない場合でも同様の結果となっています。
Localization
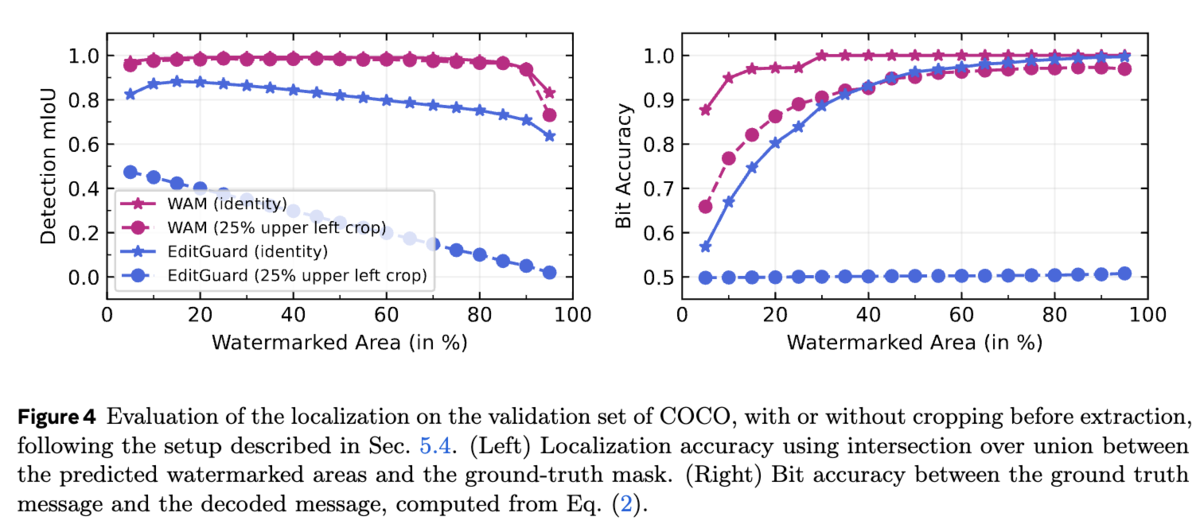
透かしの位置特定能力の評価では、透かしの位置特定機能を持つWAMとEditGuardを比較しています。 セグメンテーションの分野で一般的に用いられるmIoU(平均Intersection over Union)を用いて位置特定精度を評価した結果を図4です。 WAMは、切り取りとリサイズ後も、両方のクラス(透かし入り、透かしなし)を正確に予測できることがわかります。ビット精度に関しては、256×256画像のわずか10%が透かし入りであっても、WAMは平均で32ビット中31ビットを復元できました。さらに、25%切り取った画像の10%(全体のピクセル数の2.5%)だけが透かし入りであっても、約25ビットを復元できました。どちらの評価においても、WAMはEditGuardよりも優れた性能を示しています。
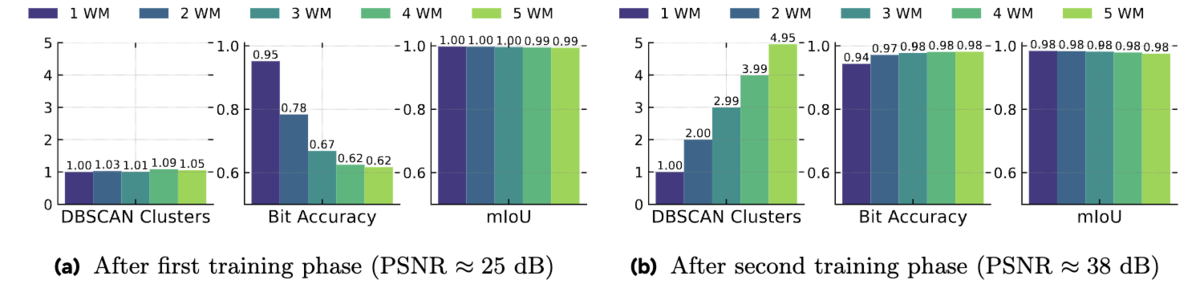
Multiple watermarks
最後に、複数透かしの検出と復号能力について評価しています。具体的には、第二フェーズの学習前後におけるWAMの性能を比較しています。 図5に示すように、第二フェーズの学習前は、メッセージが混ざり合い、WAMは全ての透かし入りピクセルに対して同じ(誤った)メッセージを予測しています。学習後は、画像のそれぞれ10%を占める領域から、最大5つの異なる32ビットメッセージを抽出できています。第二フェーズの学習では画像ごとに1〜3個の透かしを埋め込んでいますが、WAMはそれ以上の透かしにも対応できることが示されました。
最後に
Metaが発表したWatermark Anything Modelの論文について、主に背景と手法詳細、実験結果についてまとめました。Appendixでは、電子透かしの他の関連研究の詳細や、アーキテクチャ詳細なども書かれていますので、気になる方はそちらも確認すると良いと思います。また、コードや学習済みモデルもGitHubにて公開されています。
arXivの論文IDをワンクリックでコピーするブックマークレット
このブックマークレットは、以下のコードをブックマークとして保存することで利用できます。 javascript:の部分を含めて、ブックマーク名などを自由に設定して保存してください。
javascript:(function(){const url=window.location.href;const match=url.match(/\/abs\/(\d{4}\.\d{4,5})/);if(match){const arxivId=match[1];navigator.clipboard.writeText(arxivId).then(()=>alert('arXiv ID "' + arxivId + '" copied to clipboard.')).catch(()=>alert('Failed to copy arXiv ID to clipboard.'));}else{alert('Could not find arXiv ID.');}})()
このブックマークレットを使えば、論文のURLを開いている状態でブックマークをクリックするだけで、arXiv IDを簡単にコピーできます。
処理内容
やっていることは、URLから正規表現でID部分を抽出するだけです。改行をしたコードも参考までに以下に示します。
javascript:(function(){ const url = window.location.href; const match = url.match(/\/abs\/(\d{4}\.\d{4,5})/); if (match) { const arxivId = match[1]; navigator.clipboard.writeText(arxivId).then(() => { alert('arXiv ID "' + arxivId + '" copied to clipboard.'); }).catch(err => { alert('Failed to copy arXiv ID to clipboard.'); }); } else { alert('Could not find arXiv ID.'); } })();