MetaのWatermark Anything Modelの論文を読み解く
Metaが画像電子透かし技術に関する論文を発表しました。MetaのAnything Modelといえば、Segment Anything Modelがありますが、今回の論文はWatermark Anything Model。一体どのような技術なのか?論文の内容をまとめてみました。
Introのまとめ
画像電子透かし技術は、人間の目には見えない形で画像に情報を埋め込む技術です。従来は著作権保護などを目的としていましたが、近年のAI生成画像の普及に伴い、その用途は大きく変化しています。
ホワイトハウスの行政命令やEUのAI法など、各国政府はAI生成コンテンツの識別を容易にするための規制を導入しており、電子透かしはそのための重要な手段として注目されています。
しかし、従来の電子透かし技術は、画像の一部を切り貼りする「スプライシング」などの操作に対して脆弱です。例えば、電子透かしが埋め込まれた画像の一部だけを切り出して別の画像に貼り付けた場合、従来技術では電子透かしの検出が困難になります。
この論文では、これらの課題を解決するために、電子透かしをセグメンテーションタスクとして再定義した「Watermark Anything Model(WAM)」を提案しています。WAMは、画像全体ではなくピクセルごとに電子透かしの有無を判断し、埋め込まれたメッセージを抽出します。これにより、スプライシングされた画像でも電子透かしの検出・復号が可能になります。
WAMは2段階の学習プロセスを経てトレーニングされます。最初のフェーズでは低解像度画像を用いてembedderとextractorを事前学習します。embedderは、任意のn-bitメッセージを透かし信号に変換し、画像に埋め込みます。augmentorは、画像の一部に電子透かしをランダムにマスクし、その結果を一般的な処理技術(トリミング、サイズ変更、圧縮など)で補強する。一方、extractorは画像からピクセルごとに透かしの有無を判定し、メッセージを復元します。検出損失と復号損失が、学習目標として使用されます。
フェーズ2の焦点は、視認性の最小化と多重透かしへの対応です。より人間の視覚システムに合わせた、自然で目立たない透かしの埋め込みを実現します。同時に、1枚の画像に複数のメ ッセージを埋め込む能力も獲得します。この2段階の学習は、従来のadversarial networksやdivergent objectiveと比較して、不安定になりにくい。また、電子透かし画像と非電子透かし 画像の両方で抽出器を学習させる。これにより、検出の性能とロバスト性が向上する。
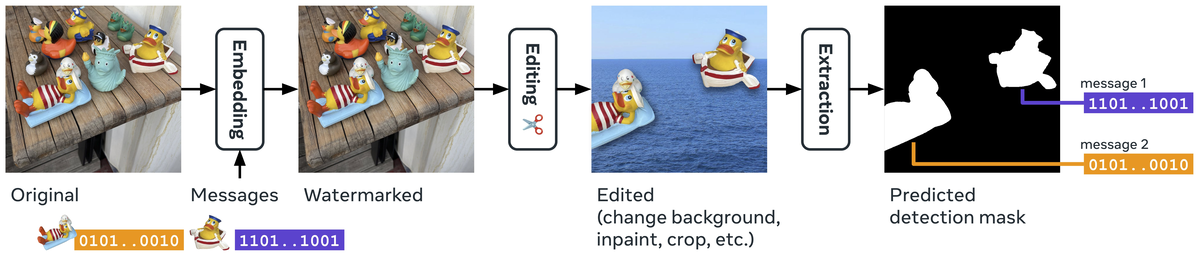
実験では、透かし検出と複合の通常のタスクについて、低解像度画像と高解像度画像で既存手法と比較し、WAMが知覚不可能性とロバスト性で競争力のある性能を達成することを示している。また、通常とは異なるタスクとして、Localization精度と単一の画像からの複数の透かしを検出・複合する能力も評価しています。
Watermark Anything Models
Model構成
WAMは、透かし埋め込み器と透かし抽出器 という2つのモデルから構成されます。
透かし埋め込み器(embedder :  )
)
embedderは、画像にメッセージを埋め込む役割を担います。その構造は、エンコーダ、メッセージ・ルックアップテーブル、デコーダの3つの要素からなります。
- エンコーダ
:入力画像を潜在空間に圧縮します。ここではLDM (Latent Diffusion Models) の変分オートエンコーダのアーキテクチャがベースとして使用されています。
- メッセージ・ルックアップテーブル
:埋め込みたいメッセージをテンソル表現に変換します。メッセージの各ビットは、その位置と値に応じてルックアップテーブルから変換される。
の埋め込みベクトルは平均化された後、潜在表現の空間サイズに合わせたテンソルになるようにリピートされます
。画像の潜在表現と連結されて、
の形状のテンソルとなる。
- デコーダ
: エンコーダからの画像潜在表現とルックアップテーブルからのメッセージテンソルを連結したものを受け取り、透かし信号
を生成します。この信号は、元の画像にスケーリングされて加算されます。スケーリング係数
は 透かし強度 と呼ばれ、元の画像への変更の度合いを制御します。最終的な透かし入り画像は、
として計算されます。
透かし抽出器(extractor:  )
)
extractorは、透かし入り画像から透かしの有無を検出し、埋め込まれたメッセージを復号する役割を担います。アーキテクチャはSETRやSegment Anythingと同様に、ViTエンコーダとピクセルデコーダの組み合わせで構成され、各ピクセルに対して次元のベクトルを出力します。
高解像度
WAMは固定解像度で動作しますが、高解像度画像にも対応可能です。埋め込み時には、入力画像を
にリサイズし、透かし信号を生成、その後でバイリニア補完により元の解像度に戻します。抽出時も同様にリサイズを行います。この方法により、低解像度画像で学習したモデルを高解像度画像に適用することが可能になり、学習に必要な計算コストを大幅に削減できます。
WAMの学習: first training phase
WAMの最初の学習フェーズでは、透かし埋め込み器と透かし抽出器を共同で学習します。その中で、 1)電子透かし画像と元画像をランダムなマスクに基づいてスプライスし、2)古典的な画像変換を適用します。以下は、詳細なフローを図で示したものです。
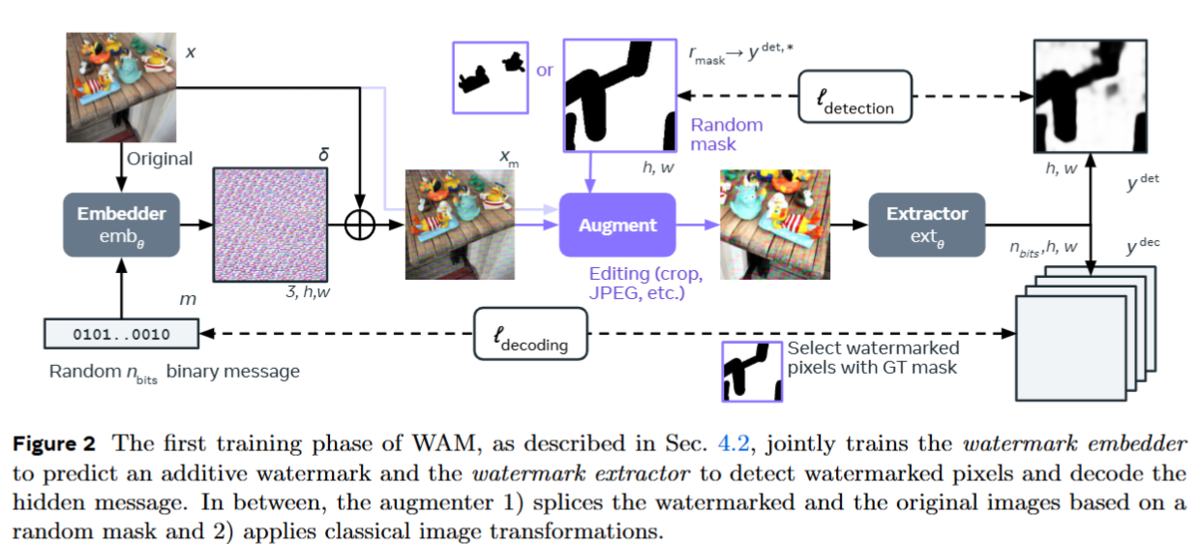
スプライシングで使われるマスクは、全領域、矩形、不規則な形状、そして学習データセットから得られるオブジェクトのセグメンテーションマップからランダムに選択されます。マスクをとすると、スプライス後の画像は
として計算されます。
は要素毎の積。
画像変換では、幾何学的な変換と値調整(ガウシアン、メディアンフィルターなど)が適用されます。幾何学変換は、透かし位置を追跡するため、マスクにも適用されます。
WAMの学習は、検出損失()と復号損失(
)の線形結合で定義される目的関数
を最小化することで行われます。
WAMの学習:Second training phase
WAMの学習の次のフェーズでは、最初のフェーズで学習したモデルをさらに洗練させ、視認性の低減と複数透かしの埋め込みという2つの重要な課題に対処します。
視認性の低減
第二フェーズではJND (Just-Noticeable-Difference) マップを活用します。JNDマップは、各ピクセルにおいて人間が知覚できる最小の人工物のモデルで、例えば平坦な領域の人工物はテクスチャのある領域よりも知覚しやすい。透かしを埋め込む際に、このJNDマップを使用することで、透かしの強度を変調して埋め込むことが可能になります。
複数透かしの埋め込み
最初のフェーズの学習では単一のメッセージしか使用されないため、異なるメッセージが埋め込まれた領域でも同じメッセージを復号する傾向があります。これを改善するために、第二フェーズでは複数のマスクを用いて学習を行います。それぞれのマスク領域に異なるメッセージを埋め込むことで、複数透かしの埋め込みに対応します。マスクの数は1から3個までで、それぞれの確率は0.6, 0.2, 0.2となっています(詳細は付録D.2)。検出損失 は、全てのマスクの和集合を正解データとして計算されます。復号損失
は、各メッセージに対して個別に計算され、その合計が全体の損失となります。
実験と結果のまとめ
この論文では、提案手法であるWAMの評価にあたり、4つの主要な項目を評価しています。
Quality
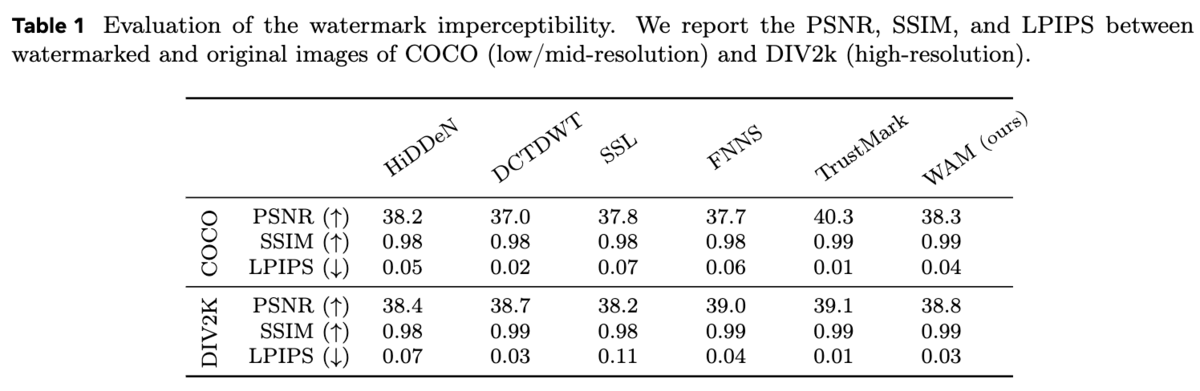
WAMによって透かしが入った画像が、元の画像と比べてどれくらい画質が変化するのか、つまり画質への影響を評価するために、PSNR、SSIM、LPIPSという3つの指標を用いて定量的に比較しています。
表1の結果から、WAMは高い画質を維持していることがわかります。これは、人間の視覚特性を考慮したJNDマップを用いることで、視覚的に敏感な領域には透かしの影響を抑え、そうでない領域に巧妙に透かしを埋め込むことで実現されています。Appendix Fには、COCOデータセットとDIV2kデータセットを用いた透かし入り画像の例が示されており、視覚的な品質の高さを確認できます。
Detection and Decoding
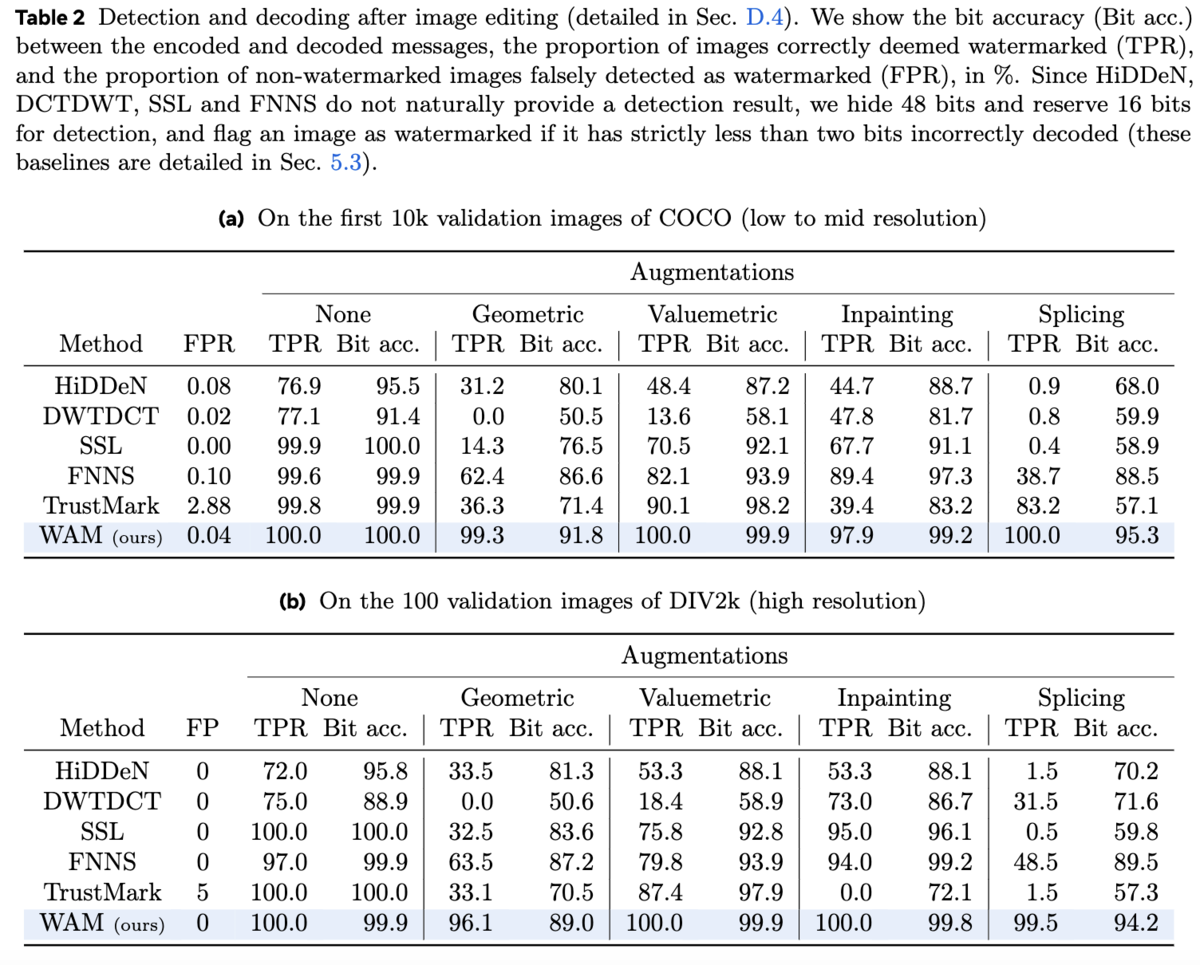
WAMの検出能力と復号能力を評価するため、DCTDWT、HiDDeN、TrustMark、SSL、FNNSといった既存の電子透かし手法と比較実験を行っています。 表2aと2bは、それぞれ低解像度/中解像度画像(COCO検証セットの最初の1万枚)と高解像度画像(DIV2k検証セット)における検出結果と復号結果を示しています。 どちらのデータセットにおいても、WAMは既存手法と比較して競争力のある性能を示し、特に従来の幾何学的変換や画質調整に対しては、より高いロバスト性を示しました。さらに重要なのは、他の手法が90%以上の真陽性率とビット精度を達成できなかったスプライシングやインペインティングに対して、WAMは優れた性能を発揮したことです。これは、WAMが高解像度画像やインペインティングに対する明示的な学習を行なっていない場合でも同様の結果となっています。
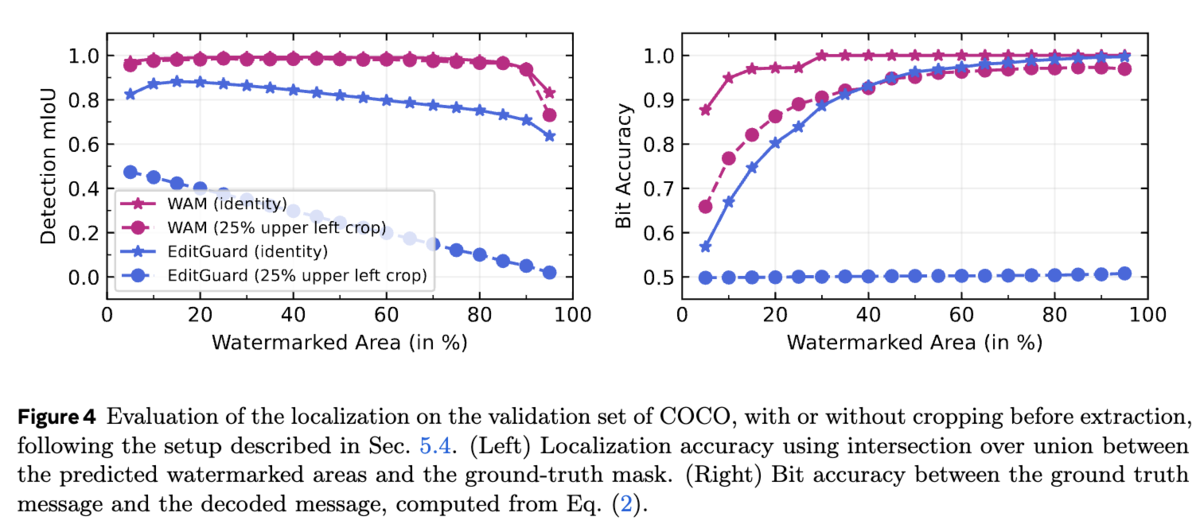
Localization
透かしの位置特定能力の評価では、透かしの位置特定機能を持つWAMとEditGuardを比較しています。 セグメンテーションの分野で一般的に用いられるmIoU(平均Intersection over Union)を用いて位置特定精度を評価した結果を図4です。 WAMは、切り取りとリサイズ後も、両方のクラス(透かし入り、透かしなし)を正確に予測できることがわかります。ビット精度に関しては、256×256画像のわずか10%が透かし入りであっても、WAMは平均で32ビット中31ビットを復元できました。さらに、25%切り取った画像の10%(全体のピクセル数の2.5%)だけが透かし入りであっても、約25ビットを復元できました。どちらの評価においても、WAMはEditGuardよりも優れた性能を示しています。
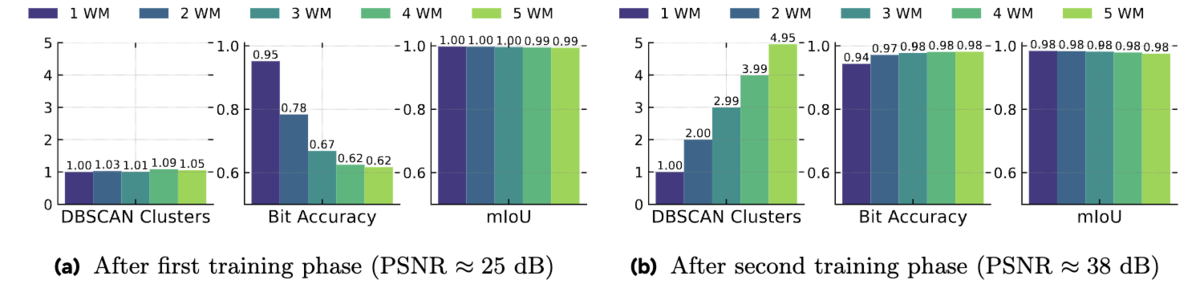
Multiple watermarks
最後に、複数透かしの検出と復号能力について評価しています。具体的には、第二フェーズの学習前後におけるWAMの性能を比較しています。 図5に示すように、第二フェーズの学習前は、メッセージが混ざり合い、WAMは全ての透かし入りピクセルに対して同じ(誤った)メッセージを予測しています。学習後は、画像のそれぞれ10%を占める領域から、最大5つの異なる32ビットメッセージを抽出できています。第二フェーズの学習では画像ごとに1〜3個の透かしを埋め込んでいますが、WAMはそれ以上の透かしにも対応できることが示されました。
最後に
Metaが発表したWatermark Anything Modelの論文について、主に背景と手法詳細、実験結果についてまとめました。Appendixでは、電子透かしの他の関連研究の詳細や、アーキテクチャ詳細なども書かれていますので、気になる方はそちらも確認すると良いと思います。また、コードや学習済みモデルもGitHubにて公開されています。